Hands-on #6: Bashoutter
Author:Anda Toshiki
Updated:6 days ago
Words:2.9k
Reading:12 min
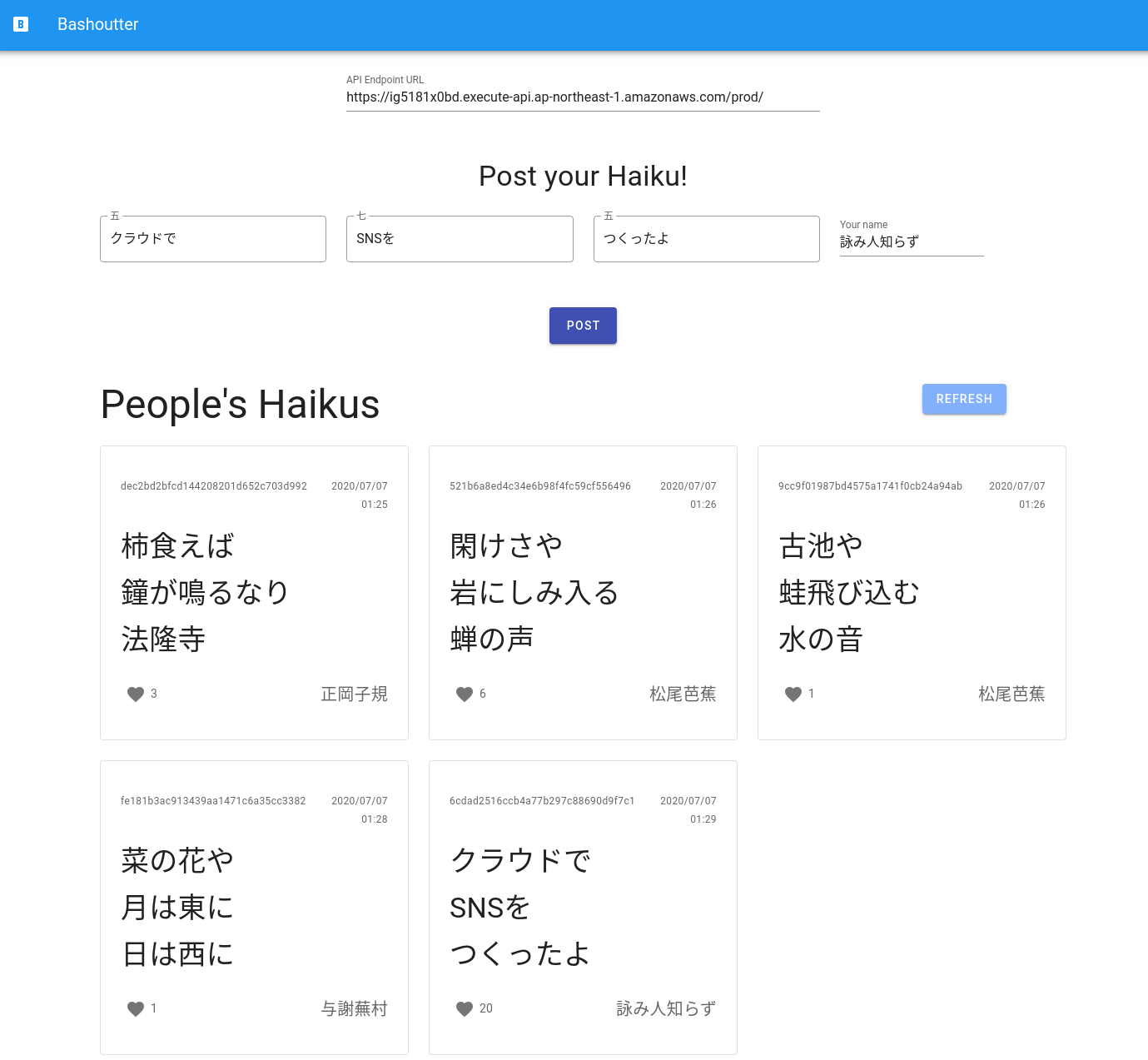
さて,最後のハンズオンとなる第六回では,これまで学んできたサーバーレスクラウドの技術を使って,簡単なウェブサービスを作ってみよう. 具体的には,人々が自分の作った俳句を投稿する SNS サービス (Bashoutter と名付ける) を作成してみよう. Lambda, DynamoDB, S3 などの技術をすべて盛り込み,シンプルながらもサーバーレスの利点を生かしたスケーラブルな SNS アプリが誕生する. 最終的には, figure_title のような,ミニマルではあるがとても現代風な SNS サイトが完成する!
準備
ハンズオンのソースコードは GitHub の handson/bashoutter に置いてある.
本ハンズオンの実行には,第一回ハンズオンで説明した準備 ( (#handson_01_prep)) が整っていることを前提とする. それ以外に必要な準備はない.
このハンズオンは,基本的に AWS の無料枠 の範囲内で実行できる.
アプリケーションの説明
API
今回のアプリケーションでは,人々からの俳句の投稿を受け付けたり,投稿された俳句の一覧を取得する,といった機能を実装したい. この機能を実現するための最小限の設計として, table_title に示すような四つの REST API を今回は実装する. 俳句を投稿する,閲覧する,削除するという基本的なデータ操作を行うための API が完備されている. また, PATCH /haiku/{item_id} は, {item_id} で指定された俳句に”いいね”をするために使用する.
| 俳句の一覧を取得する |
| 新しい俳句を投稿する |
|
|
|
|
それぞれの API のパラメータおよび返り値の詳細は,ハンズオンのソースコードの中の swagger.yml に定義してある.
Open API Specification (OAS; 少し前は Swagger Specification とよばれていた) は, REST API のための記述フォーマットである. OAS に従って API の仕様が記述されていると,簡単にドキュメンテーションを生成したり,クライアントアプリケーションを自動生成することができる. 今回用意した API 仕様 も, OAS に従って書いてある. 詳しくは Swagger の公式ドキュメンテーション などを参照.
アプリケーションアーキテクチャ
このハンズオンで作成するアプリケーションの概要を figure_title に示す.
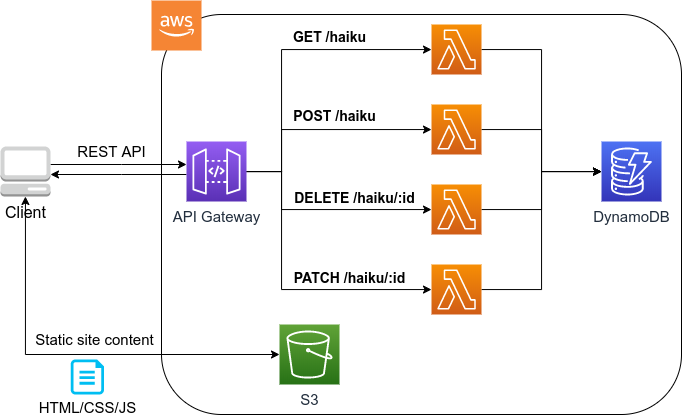
簡単にまとめると,次のような設計である.
クライアントからの API リクエストは, API Gateway (後述)にまず送信され, API の URI で指定された Lambda 関数へ転送される.
それぞれの API のパス (リソース) ごとに独立した Lambda を用意する.
俳句の情報 (作者,本文,投稿日時など) を記録するためのデータベース (DynamoDB) を用意する.
各 Lambda 関数には, DynamoDB へのアクセス権を付与する.
最後に,ウェブブラウザからコンテンツを表示できるよう, ウェブページの静的コンテンツを配信するための S3 バケットを用意する.クライアントはこの S3 バケットにアクセスすることで HTML/CSS/JS などのコンテンツを取得する.
それでは,プログラムのソースコードを見てみよう (handson/bashoutter/app.py).
python
class Bashoutter(core.Stack):
def __init__(self, scope: core.App, name: str, **kwargs) -> None:
super().__init__(scope, name, **kwargs)
#
# dynamoDB table to store haiku
table = ddb.Table(
self, "Bashoutter-Table",
partition_key=ddb.Attribute(
name="item_id",
type=ddb.AttributeType.STRING
),
billing_mode=ddb.BillingMode.PAY_PER_REQUEST,
removal_policy=core.RemovalPolicy.DESTROY
)
#
bucket = s3.Bucket(
self, "Bashoutter-Bucket",
website_index_document="index.html",
public_read_access=True,
removal_policy=core.RemovalPolicy.DESTROY
)
common_params = {
"runtime": _lambda.Runtime.PYTHON_3_7,
"environment": {
"TABLE_NAME": table.table_name
}
}
#
# define Lambda functions
get_haiku_lambda = _lambda.Function(
self, "GetHaiku",
code=_lambda.Code.from_asset("api"),
handler="api.get_haiku",
memory_size=512,
**common_params,
)
post_haiku_lambda = _lambda.Function(
self, "PostHaiku",
code=_lambda.Code.from_asset("api"),
handler="api.post_haiku",
**common_params,
)
patch_haiku_lambda = _lambda.Function(
self, "PatchHaiku",
code=_lambda.Code.from_asset("api"),
handler="api.patch_haiku",
**common_params,
)
delete_haiku_lambda = _lambda.Function(
self, "DeleteHaiku",
code=_lambda.Code.from_asset("api"),
handler="api.delete_haiku",
**common_params,
)
#
# grant permissions
table.grant_read_data(get_haiku_lambda)
table.grant_read_write_data(post_haiku_lambda)
table.grant_read_write_data(patch_haiku_lambda)
table.grant_read_write_data(delete_haiku_lambda)
#
# define API Gateway
api = apigw.RestApi(
self, "BashoutterApi",
default_cors_preflight_options=apigw.CorsOptions(
allow_origins=apigw.Cors.ALL_ORIGINS,
allow_methods=apigw.Cors.ALL_METHODS,
)
)
haiku = api.root.add_resource("haiku")
haiku.add_method(
"GET",
apigw.LambdaIntegration(get_haiku_lambda)
)
haiku.add_method(
"POST",
apigw.LambdaIntegration(post_haiku_lambda)
)
haiku_item_id = haiku.add_resource("{item_id}")
haiku_item_id.add_method(
"PATCH",
apigw.LambdaIntegration(patch_haiku_lambda)
)
haiku_item_id.add_method(
"DELETE",
apigw.LambdaIntegration(delete_haiku_lambda)
)class Bashoutter(core.Stack):
def __init__(self, scope: core.App, name: str, **kwargs) -> None:
super().__init__(scope, name, **kwargs)
#
# dynamoDB table to store haiku
table = ddb.Table(
self, "Bashoutter-Table",
partition_key=ddb.Attribute(
name="item_id",
type=ddb.AttributeType.STRING
),
billing_mode=ddb.BillingMode.PAY_PER_REQUEST,
removal_policy=core.RemovalPolicy.DESTROY
)
#
bucket = s3.Bucket(
self, "Bashoutter-Bucket",
website_index_document="index.html",
public_read_access=True,
removal_policy=core.RemovalPolicy.DESTROY
)
common_params = {
"runtime": _lambda.Runtime.PYTHON_3_7,
"environment": {
"TABLE_NAME": table.table_name
}
}
#
# define Lambda functions
get_haiku_lambda = _lambda.Function(
self, "GetHaiku",
code=_lambda.Code.from_asset("api"),
handler="api.get_haiku",
memory_size=512,
**common_params,
)
post_haiku_lambda = _lambda.Function(
self, "PostHaiku",
code=_lambda.Code.from_asset("api"),
handler="api.post_haiku",
**common_params,
)
patch_haiku_lambda = _lambda.Function(
self, "PatchHaiku",
code=_lambda.Code.from_asset("api"),
handler="api.patch_haiku",
**common_params,
)
delete_haiku_lambda = _lambda.Function(
self, "DeleteHaiku",
code=_lambda.Code.from_asset("api"),
handler="api.delete_haiku",
**common_params,
)
#
# grant permissions
table.grant_read_data(get_haiku_lambda)
table.grant_read_write_data(post_haiku_lambda)
table.grant_read_write_data(patch_haiku_lambda)
table.grant_read_write_data(delete_haiku_lambda)
#
# define API Gateway
api = apigw.RestApi(
self, "BashoutterApi",
default_cors_preflight_options=apigw.CorsOptions(
allow_origins=apigw.Cors.ALL_ORIGINS,
allow_methods=apigw.Cors.ALL_METHODS,
)
)
haiku = api.root.add_resource("haiku")
haiku.add_method(
"GET",
apigw.LambdaIntegration(get_haiku_lambda)
)
haiku.add_method(
"POST",
apigw.LambdaIntegration(post_haiku_lambda)
)
haiku_item_id = haiku.add_resource("{item_id}")
haiku_item_id.add_method(
"PATCH",
apigw.LambdaIntegration(patch_haiku_lambda)
)
haiku_item_id.add_method(
"DELETE",
apigw.LambdaIntegration(delete_haiku_lambda)
)ここで,俳句の情報を記録しておくための DynamoDB テーブルを定義している.
静的コンテンツを配信するための S3 バケットを用意している.
それぞれの API で実行される Lambda 関数を定義している. 関数は Python3.7 で書かれており,コードは handson/bashoutter/api/api.py にある.
<3> で定義された Lambda 関数に対し,データベースへの読み書きのアクセス権限を付与している.
ここで,API Gateway により,各 API パスとそこで実行されるべき Lambda 関数を紐付けている.
それぞれの項目について,もう少し詳しく説明しよう.
Public access mode の S3 バケット
S3 のバケットを作成しているコードを見てみよう.
python
bucket = s3.Bucket(
self, "Bashoutter-Bucket",
website_index_document="index.html",
public_read_access=True,
removal_policy=core.RemovalPolicy.DESTROY
)bucket = s3.Bucket(
self, "Bashoutter-Bucket",
website_index_document="index.html",
public_read_access=True,
removal_policy=core.RemovalPolicy.DESTROY
)ここで注目してほしいのは public_read_access=True の部分だ. 前章で, S3 について説明を行ったときには触れなかったが, S3 には Public access mode という機能がある. Public access mode をオンにしておくと,バケットの中のファイルは認証なしで (i.e. インターネット上の誰でも) 閲覧できるようになる. この設定は,一般公開されているウェブサイトの静的なコンテンツを置いておくのに最適であり,多くのサーバーレスによるウェブサービスでこのような設計が行われる. public access mode を設定しておくと, http://XXXX.s3-website-ap-northeast-1.amazonaws.com/ のような固有の URL がバケットに対して付与される. そして,クライアントがこの URL にアクセスをすると,バケットの中にある index.html がクライアントに返され,ページがロードされる (どのファイルが返されるかは, website_index_document="index.html" の部分で設定している.)
なお,この時点ではバケットは空である. HTML/CSS/JS など静的コンテンツの配置は,デプロイを行った後ほどのステップで行う.
より本格的なウェブページを運用する際には, public access mode の S3 バケットに, CloudFront という機能を追加することが一般的である. CloudFront により, Content Delivery Nework (CDN) や暗号化された HTTPS 通信を設定することができる. CloudFront についての詳細は 公式ドキュメンテーション "What is Amazon CloudFront?" などを参照いただきたい.
今回のハンズオンでは説明の簡略化のため CloudFront の設定を行わなかったが,興味のある読者は次のリンクのプログラムが参考になるだろう.
今回の S3 バケットには, AWS によって付与されたランダムな URL がついている. これを. example.com のような自分のドメインでホストしたければ, AWS によって付与された URL を自分のドメインの DNS レコードに追加すればよい.
API のハンドラ関数
API リクエストが来たときに,リクエストされた処理を行う関数のことをハンドラ (handler) 関数とよぶ. GET /haiku の API に対してのハンドラ関数を Lambda で定義している部分を見てみよう.
python
get_haiku_lambda = _lambda.Function(
self, "GetHaiku",
code=_lambda.Code.from_asset("api"),
handler="api.get_haiku",
memory_size=512,
**common_params
)get_haiku_lambda = _lambda.Function(
self, "GetHaiku",
code=_lambda.Code.from_asset("api"),
handler="api.get_haiku",
memory_size=512,
**common_params
)簡単なところから見ていくと, memory_size=512 の箇所でメモリーの使用量を 512MB に指定している. また, code=_lambda.Code.from_asset("api") によって外部のディレクトリ (api/) を参照せよと指定しており, handler="api.get_haiku" のところで api.py というファイルの get_haiku() という関数をハンドラ関数として実行せよ,と定義している.
次に,ハンドラ関数として使用されている get_haiku() のコードを見てみよう (handson/bashoutter/api/api.py).
python
ddb = boto3.resource("dynamodb")
table = ddb.Table(os.environ["TABLE_NAME"])
def get_haiku(event, context):
"""
handler for GET /haiku
"""
try:
response = table.scan()
status_code = 200
resp = response.get("Items")
except Exception as e:
status_code = 500
resp = {"description": f"Internal server error. {str(e)}"}
return {
"statusCode": status_code,
"headers": HEADERS,
"body": json.dumps(resp, cls=DecimalEncoder)
}ddb = boto3.resource("dynamodb")
table = ddb.Table(os.environ["TABLE_NAME"])
def get_haiku(event, context):
"""
handler for GET /haiku
"""
try:
response = table.scan()
status_code = 200
resp = response.get("Items")
except Exception as e:
status_code = 500
resp = {"description": f"Internal server error. {str(e)}"}
return {
"statusCode": status_code,
"headers": HEADERS,
"body": json.dumps(resp, cls=DecimalEncoder)
}response = table.scan() で,俳句の格納された DynamoDB テーブルから,すべての要素を取り出している. もしなにもエラーが起きなければステータスコード 200 が返され,もしなにかエラーが起こればステータスコード 500 が返されるようになっている.
上記のような操作を,ほかの API についても繰り返すことで,すべての API のハンドラ関数が定義されている.
GET /haiku のハンドラ関数で, response = table.scan() という部分があるが,実はこれは最善の書き方ではない. DynamoDB の scan() メソッドは,最大で 1MB までのデータしか返さない. データベースのサイズが大きく, 1MB 以上のデータがある場合には,再帰的に scan() メソッドをよぶ必要がある. 詳しくは boto3 ドキュメンテーション を参照.
AWS における権限の管理 (IAM)
以下の部分のコードに注目してほしい.
python
table.grant_read_data(get_haiku_lambda)
table.grant_read_write_data(post_haiku_lambda)
table.grant_read_write_data(patch_haiku_lambda)
table.grant_read_write_data(delete_haiku_lambda)table.grant_read_data(get_haiku_lambda)
table.grant_read_write_data(post_haiku_lambda)
table.grant_read_write_data(patch_haiku_lambda)
table.grant_read_write_data(delete_haiku_lambda)これまでは説明の簡略化のためにあえて触れてこなかったが, AWS には IAM (Identity and Access Management) という重要な概念がある. IAM は基本的に,あるリソースがほかのリソースに対してどのような権限をもっているか,を規定するものである. Lambda は,デフォルトの状態ではほかのリソースにアクセスする権限をなにも有していない. したがって, Lambda 関数が DynamoDB のデータを読み書きするためには,それを許可するような IAM が Lambda 関数に付与されていなければならない.今回の S3 バケットには, AWS によって付与されたランダムな URL がついている. これを. example.com のような自分のドメインでホストしたければ, AWS によって付与された URL を自分のドメインの DNS レコードに追加すればよい.
CDK による dynamodb.Table オブジェクトには grant_read_write_data() という便利なメソッドが備わっており,アクセスを許可したい Lambda 関数を引数としてこのメソッドを呼ぶことで,データベースへの読み書きを許可する IAM を付与することができる. 同様に,CDK の s3.Bucket オブジェクトにも grant_read_write() というメソッドが備わっており,これによってバケットへの読み書きを許可することができる. このメソッドは,実は (#sec_aws_batch) で AWS Batch によるクラスターを構成した際に使用した. 興味のある読者は振り返ってコードを確認してみよう.
各リソースに付与する IAM は,必要最低限の権限を与えるにとどめるというのが基本方針である. これにより,セキュリティを向上させるだけでなく,意図していないプログラムからのデータベースへの読み書きを防止するという点で,バグを未然に防ぐことができる.
そのような理由により,このコードでは GET のハンドラー関数に対しては grant_read_data() によって, read 権限のみを付与している.
API Gateway
API Gateway とは, API の"入り口"として,API のリクエストパスに従って Lambda や EC2 などに接続を行うという機能を担う (figure_title). Lambda や EC2 によって行われた処理の結果は,再び API Gateway を経由してクライアントに返される. このように,クライアントとバックエンドサーバーの間に立ち, API のリソースパスに応じて接続先を振り分けるようなサーバーをルーター,あるいはリバースプロキシとよんだりする. 従来的には,ルーターにはそれ専用の仮想サーバーが置かれることが一般的であった. しかし, API Gateway はサーバーレスなルーターとして,固定されたサーバーを配置することなく, API のリクエストが来たときのみ起動し,API のルーティングを実行する. サーバーレスであることの当然の帰結として,アクセスの件数が増大したときにはそれにルーティングの処理能力を自動で増やす機能も備わっている.
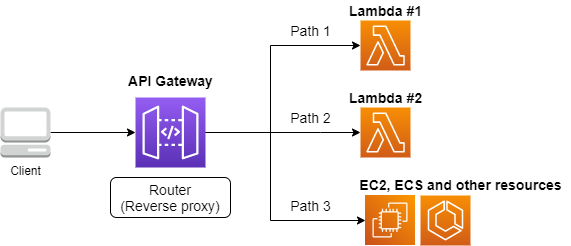
API Gateway を配置することで,大量 (1 秒間に数千から数万件) の API リクエストに対応することのできるシステムを容易に構築することができる. API Gateway の料金は table_title のように設定されている. また,無料利用枠により,月ごとに 100 万件までのリクエストは 0 円で利用できる.
| Number of Requests (per month) | Price (per million) |
|---|---|
First 333 million | $4.25 |
Next 667 million | $3.53 |
Next 19 billion | $3.00 |
Over 20 billion | $1.91 |
ソースコードの該当箇所を見てみよう.
python
#
api = apigw.RestApi(
self, "BashoutterApi",
default_cors_preflight_options=apigw.CorsOptions(
allow_origins=apigw.Cors.ALL_ORIGINS,
allow_methods=apigw.Cors.ALL_METHODS,
)
)
#
haiku = api.root.add_resource("haiku")
#
haiku.add_method(
"GET",
apigw.LambdaIntegration(get_haiku_lambda)
)
haiku.add_method(
"POST",
apigw.LambdaIntegration(post_haiku_lambda)
)
#
haiku_item_id = haiku.add_resource("{item_id}")
#
haiku_item_id.add_method(
"PATCH",
apigw.LambdaIntegration(patch_haiku_lambda)
)
haiku_item_id.add_method(
"DELETE",
apigw.LambdaIntegration(delete_haiku_lambda)
)#
api = apigw.RestApi(
self, "BashoutterApi",
default_cors_preflight_options=apigw.CorsOptions(
allow_origins=apigw.Cors.ALL_ORIGINS,
allow_methods=apigw.Cors.ALL_METHODS,
)
)
#
haiku = api.root.add_resource("haiku")
#
haiku.add_method(
"GET",
apigw.LambdaIntegration(get_haiku_lambda)
)
haiku.add_method(
"POST",
apigw.LambdaIntegration(post_haiku_lambda)
)
#
haiku_item_id = haiku.add_resource("{item_id}")
#
haiku_item_id.add_method(
"PATCH",
apigw.LambdaIntegration(patch_haiku_lambda)
)
haiku_item_id.add_method(
"DELETE",
apigw.LambdaIntegration(delete_haiku_lambda)
)最初に,
api = apigw.RestApi()により,空の API Gateway を作成している.次に,
api.root.add_resource()のメソッドを呼ぶことで,/haikuという API パスを追加している.続いて,
add_method()を呼ぶことで,GET,POSTのメソッドを/haikuのパスに定義している.さらに,
haiku.add_resource("{item_id}")により,/haiku/{item_id}という API パスを追加している.最後に,
add_method()を呼ぶことにより,PATCH,DELETEのメソッドを/haiku/{item_id}のパスに定義している.
このように, API Gateway の使い方は非常にシンプルで,逐次的に API パスとそこで実行されるメソッド・Lambda を記述していくだけでよい.
このプログラムで 新規 API を作成すると, ランダムな URL がその API のエンドポイントとして割り当てられる. これを. api.example.com のような自分のドメインでホストしたければ, AWS によって付与された URL を自分のドメインの DNS レコードに追加すればよい.
API Gateway で新規 API を作成したとき, default_cors_preflight_options= というパラメータで Cross Origin Resource Sharing (CORS) の設定を行っている. これは,ブラウザで走る Web アプリケーションと API を接続するときに必要な設定である.
アプリケーションのデプロイ
アプリケーションの中身が理解できたところで,早速デプロイを行ってみよう. デプロイの手順は,これまでのハンズオンとほとんど共通である. ここでは,コマンドのみ列挙する (# で始まる行はコメントである). シークレットキーの設定も忘れずに ( (#aws_cli_install)).
sh
# プロジェクトのディレクトリに移動
$ cd intro-aws/handson/bashoutter
# venv を作成し,依存ライブラリのインストールを行う
$ python3 -m venv .env
$ source .env/bin/activate
$ pip install -r requirements.txt
# デプロイを実行
$ cdk deploy# プロジェクトのディレクトリに移動
$ cd intro-aws/handson/bashoutter
# venv を作成し,依存ライブラリのインストールを行う
$ python3 -m venv .env
$ source .env/bin/activate
$ pip install -r requirements.txt
# デプロイを実行
$ cdk deployデプロイのコマンドが無事に実行されれば, figure_title のような出力が得られるはずである. ここで表示されている Bashoutter.BashoutterApiEndpoint = XXXX, Bashoutter.BucketUrl = YYYY の二つ文字列はあとで使うのでメモしておこう.

AWS コンソールにログインして,デプロイされたスタックを確認してみよう. まずは,コンソールから API Gateway のページに行く. すると, figure_title のような画面が表示され,デプロイ済みの API エンドポイントの一覧が確認できる.
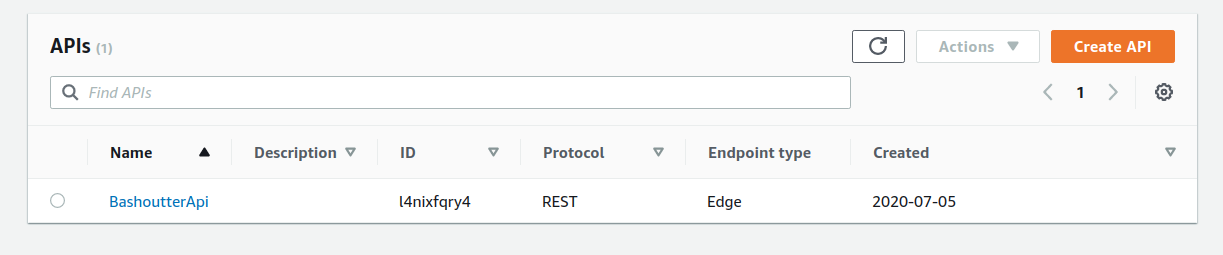
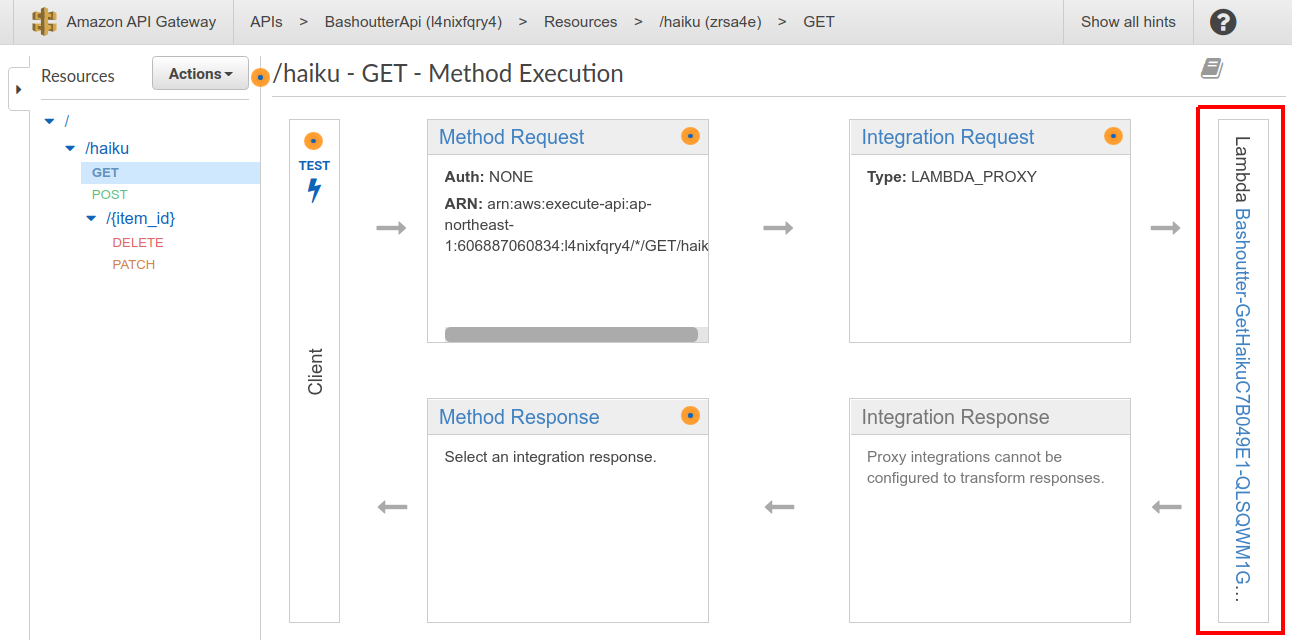
今回デプロイした "BashoutterApi" という名前の API をクリックすることで figure_title のような画面に遷移し,詳細情報を閲覧できる. GET /haiku, POST /haiku などが定義されていることが確認できる.
それぞれのメソッドをクリックすると,そのメソッドの詳細情報を確認できる. API Gateway は,前述したルーティングの機能だけでなく,認証機能などを追加することも可能である. このハンズオンではとくにこれらの機能は使用しないが, "Method Request" と書いてある項目などがそれに相当する. 次に, figure_title で画面右端の赤色で囲った部分に,この API で呼ばれる Lambda 関数が指定されていることに注目しよう. 関数名をクリックと,該当する Lambda のコンソールに遷移し,関数の中身を閲覧することが可能である.
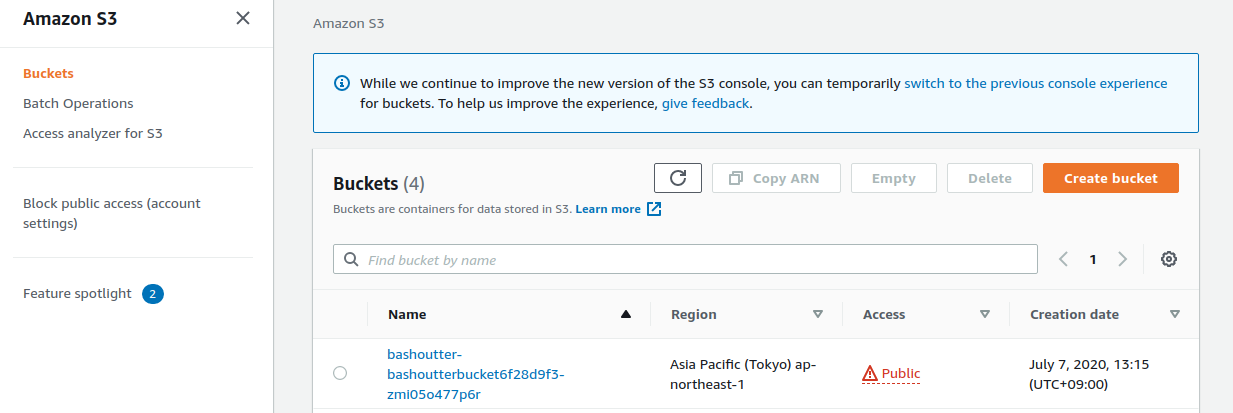
次に, S3 のコンソール画面に移ってみよう. bashouter- で始まるランダムな名前のバケットが見つかるはずである (figure_title).
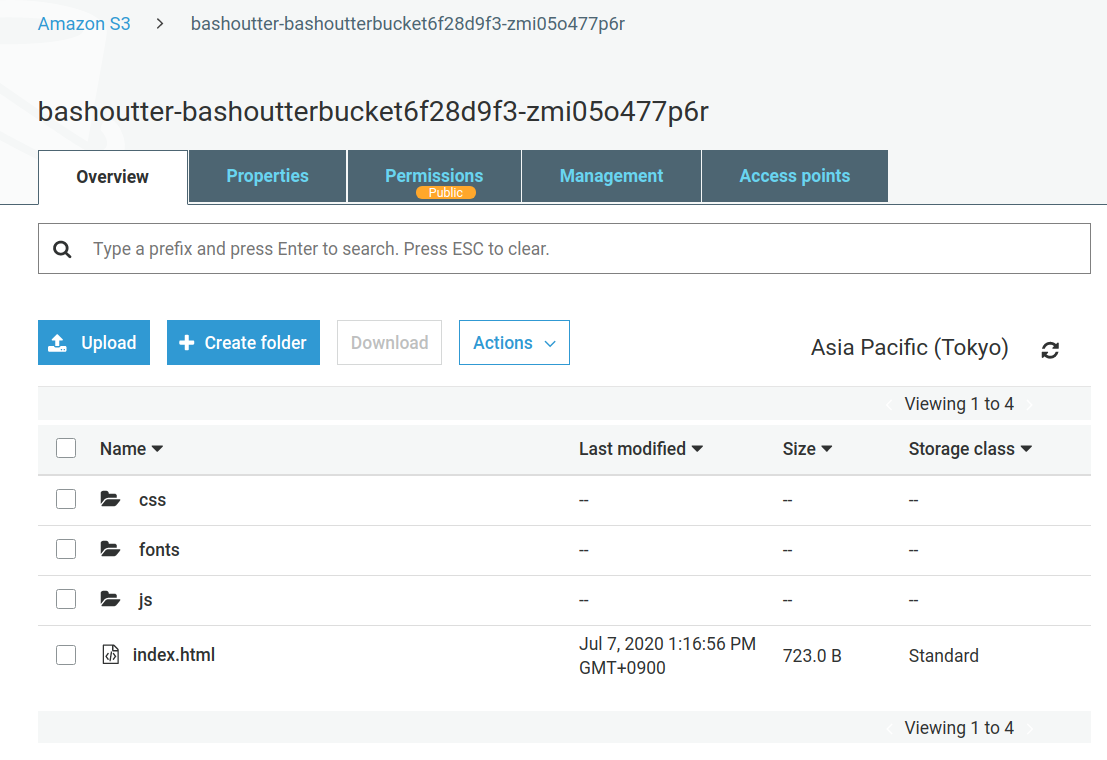
バケットの名前をクリックすることで,バケットの中身を確認してみよう. index.html のほか, css/, js/ などのディレクトリがあるのが確認できるだろう (figure_title). これらが,ウェブページの"枠"を定義している静的コンテンツである.
API リクエストを送信する
それでは,デプロイしたアプリケーションに対し,実際に API リクエストを送信してみよう. まずはコマンドラインから API を送信する演習を行おう. S3 に配置した GUI は一旦おいておく.
ここではコマンドラインから HTTP API リクエストを送信するためのシンプルな HTTP クライアントである HTTPie を使ってみよう. HTTPie は,スタックをデプロイするときに Python 仮想環境 (venv) を作成したとき,一緒にインストールされている. 念のためインストールがうまくいっているか確認するには,仮想環境を立ち上げたあとコマンドラインに http と打ってみる. ヘルプのメッセージが出力されたら準備 OK である.
まず,先ほどデプロイを実行したときに得られた API のエンドポイントの URL (Bashoutter.BashoutterApiEndpoint = XXXX で得られた XXXX の文字列) をコマンドラインの変数に設定しておく.
sh
$ export ENDPOINT_URL=XXXX$ export ENDPOINT_URL=XXXX次に,俳句の一覧を取得するため, GET /haiku の API を送信してみよう.
sh
$ http GET "${ENDPOINT_URL}/haiku"$ http GET "${ENDPOINT_URL}/haiku"現時点では,まだだれも俳句を投稿していないので,空の配列 ([]) が返ってくる.
それでは次に, POST /haiku を使って俳句を投稿してみよう.
sh
$ http POST "${ENDPOINT_URL}/haiku" \
username="松尾芭蕉" \
first="閑さや" \
second="岩にしみ入る" \
third="蝉の声"$ http POST "${ENDPOINT_URL}/haiku" \
username="松尾芭蕉" \
first="閑さや" \
second="岩にしみ入る" \
third="蝉の声"次のような出力が得られるだろう.
sh
HTTP/1.1 201 Created
Connection: keep-alive
Content-Length: 49
Content-Type: application/json
....
{
"description": "Successfully added a new haiku"
}HTTP/1.1 201 Created
Connection: keep-alive
Content-Length: 49
Content-Type: application/json
....
{
"description": "Successfully added a new haiku"
}新しい俳句を投稿することに成功したようである. 本当に俳句が追加されたか,再び GET リクエストを呼ぶことで確認してみよう.
sh
$ http GET "${ENDPOINT_URL}/haiku"
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 258
Content-Type: application/json
...
[
{
"created_at": "2020-07-06T02:46:04+00:00",
"first": "閑さや",
"item_id": "7e91c5e4d7ad47909e0ac14c8bbab05b",
"likes": 0.0,
"second": "岩にしみ入る",
"third": "蝉の声",
"username": "松尾芭蕉"
}
]$ http GET "${ENDPOINT_URL}/haiku"
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 258
Content-Type: application/json
...
[
{
"created_at": "2020-07-06T02:46:04+00:00",
"first": "閑さや",
"item_id": "7e91c5e4d7ad47909e0ac14c8bbab05b",
"likes": 0.0,
"second": "岩にしみ入る",
"third": "蝉の声",
"username": "松尾芭蕉"
}
]素晴らしい!
次に, PATCH /haiku/{item_id} を呼ぶことでこの俳句にいいねを追加してみよう. 一つ前のコマンドで取得した俳句の item_id を,次のコマンドの XXXX に代入した上で実行しよう.
sh
$ http PATCH "${ENDPOINT_URL}/haiku/XXXX"$ http PATCH "${ENDPOINT_URL}/haiku/XXXX"{"description": "OK"} という出力が得られるはずである. 再び GET リクエストを送ることで,いいね (likes) が 1 増えたことを確認しよう.
sh
$ http GET "${ENDPOINT_URL}/haiku"
...
[
{
...
"likes": 1.0,
...
}
]$ http GET "${ENDPOINT_URL}/haiku"
...
[
{
...
"likes": 1.0,
...
}
]最後に, DELETE リクエストを送ることで俳句をデータベースから削除しよう. XXXX は item_id の値で置き換えたうえで次のコマンドを実行する.
sh
$ http DELETE "${ENDPOINT_URL}/haiku/XXXX"$ http DELETE "${ENDPOINT_URL}/haiku/XXXX"再び GET リクエストを送ることで,返り値が空 ([]) になっていることを確認しよう.
これで,俳句の投稿・取得・削除そしていいねの追加,といった基本的な API がきちんと動作していることが確認できた.
大量の API リクエストをシミュレートする
さて,前節ではマニュアルで一つずつ俳句を投稿した. 多数のユーザーがいるような SNS では,1 秒間に数千件以上の投稿がされている. 今回はサーバーレスアーキテクチャを採用したことで,そのような瞬間的な大量アクセスにも容易に対応できるようなシステムが自動的に構築されている. このポイントを実証するため,ここでは大量の API が送信された状況をシミュレートしてみよう.
handson/bashoutter/client.py に,大量の API リクエストをシミュレートするためのプログラムが書かれている. このプログラムを使用すると, POST /haiku の API リクエストを指定された回数だけ実行することができる.
テストとして, API を 300 回実行してみよう. 次のコマンドを実行する.
sh
$ python client.py $ENDPOINT_URL post_many 300$ python client.py $ENDPOINT_URL post_many 300数秒のうちに実行が完了するだろう. これがもし,単一のサーバーからなる API だったとしたら,このような大量のリクエストの処理にはもっと時間がかかっただろう. 最悪の場合には,サーバーダウンにもつながっていたかもしれない. したがって,今回作成したサーバーレスアプリケーションは,とてもシンプルながらも 1 秒間に数百件の処理を行えるような,スケーラブルなクラウドシステムであることがわかる. サーバーレスでクラウドを設計することの利点を垣間見ることができただろうか?
先述のコマンドにより大量の俳句を投稿するとデータベースに無駄なデータがどんどん溜まってしまう. データベースを完全に空にするには,次のコマンドを使用する.
sh
$ python client.py $ENDPOINT_URL clear_database$ python client.py $ENDPOINT_URL clear_databaseBashoutter GUI を動かしてみる
前節ではコマンドラインから API を送信する演習を行った. ウェブアプリケーションでは,これと同じことがウェブブラウザの背後で行われ,ページのコンテンツが表示されている ( (#fig:web_server) 参照). 最後に, API が GUI と統合されるとどうなるのか,見てみよう.
CDK のコードで, Public access mode の S3 バケットを作成したことを思い出してほしい. 最初のステップとして,ここにウェブサイトのコンテンツをアップロードしよう. ハンズオンのソースコードの中に gui/dist というフォルダが見つかるはずである. ここにはビルド済みのウェブサイトの静的コンテンツ (HTML/CSS/JavaScript) が入っている. AWS CLI のコマンドを使うことでこれらのファイルを S3 にアップロードしよう.
sh
$ aws s3 cp --recursive ./gui/dist s3://<BUCKET_NAME>$ aws s3 cp --recursive ./gui/dist s3://<BUCKET_NAME>コマンドを実行する際は, Bashoutter ハンズオンのディレクトリから行うこと (./gui/dist に注目),そして <BUCKET_NAME> にはデプロイした自身のバケットの名前が入る点に注意. 念のため,AWS コンソールにログインし,バケットにファイルがアップロードされている点を確認しておこう.
なお,今回は GUI の説明はとくに行わないが, Bashoutter のウェブサイトは Vue.js と Vuetify という UI フレームワークを使って作成した. Vue を使うことで, Single page application (SPA) の技術でウェブサイトの画面がレンダリングされる. ソースコードは handson/bashoutter/gui のディレクトリの中にあるので,興味のある読者は確認してみるとよい.
アップトードが完了したところで,続いてデプロイを実行したときにコマンドラインの出力を見直してみよう. Bashoutter.BucketUrl= で与えられた URL が見つかるはずである (figure_title). これは,先述したとおり, Public access mode の S3 バケットの URL である.
ウェブブラウザを開き,アドレスバーに S3 の URL を入力しへアクセスしてみよう. すると, figure_title のようなページが表示されるはずである.
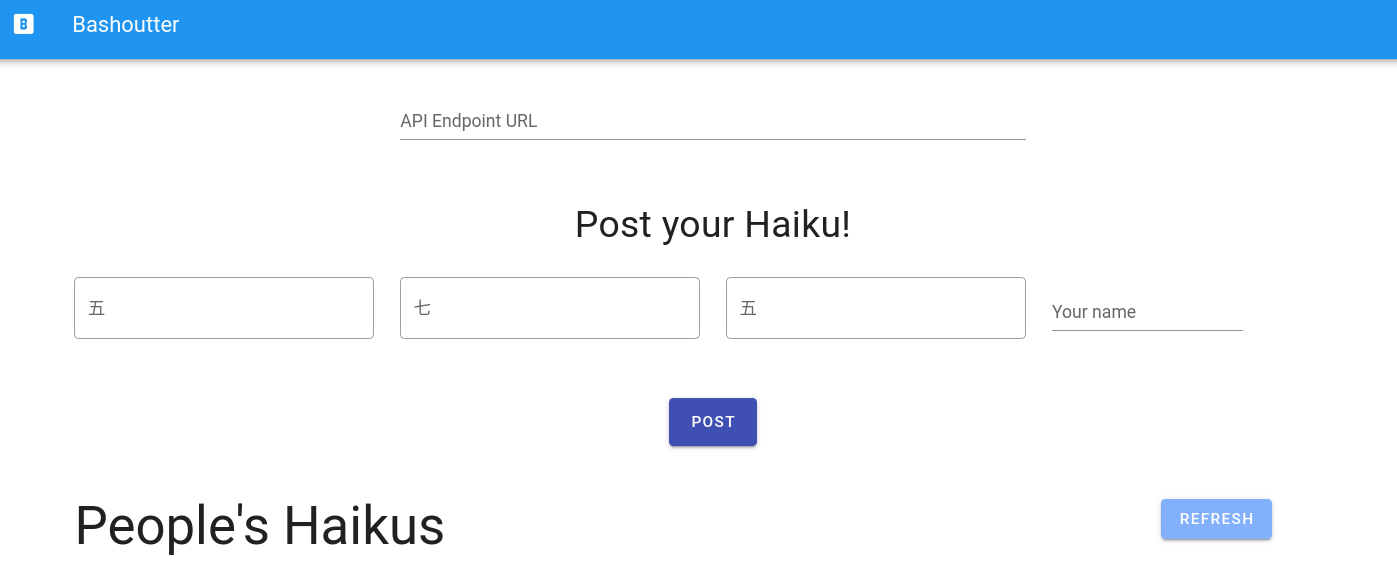
ページが表示されたら,一番上の "API Endpoint URL" と書いてあるテキストボックスに,今回デプロイした API Gateway の URL を入力する (今回のアプリケーションでは,API Gateway の URL はランダムに割り当てられるのでこのような GUI の仕様になっている). そうしたら,画面の "REFRESH" と書いてあるボタンを押してみよう. データベースに俳句が登録済みであれば,俳句の一覧が表示されるはずである. 各俳句の左下にあるハートのアイコンをクリックすることで, "like" の票を入れることができる.
新しい俳句を投稿するには,五七五と投稿者の名前を入力して, "POST" を押す. "POST" を押した後は,再び "REFRESH" ボタンを押すことで最新の俳句のリストをデータベースから取得する.
アプリケーションの削除
これで, Bashoutter プロジェクトが完成した! この SNS は,インターネットを通じて世界のどこからでもアクセスできる状態にある. また, 大量の API リクエストをシミュレートする で見たように,大量のユーザーの同時アクセスによる負荷がかかっても,柔軟にスケールが行われ遅延なく処理を行うことができる. 極めて簡素ながらも,立派なウェブサービスとしてのスペックは満たしているのである!
Bashoutter アプリを存分に楽しむことができたら,最後に忘れずにスタックを削除しよう.
コマンドラインからスタックの削除を実行するには,次のコマンドを使う.
sh
$ cdk destroy$ cdk destroyCDK のバージョンによっては S3 のバケットが空でないと, cdk destroy がエラーを出力する場合がある. この場合はスタックを削除する前に, S3 バケットの中身をすべて削除しなければならない.
コンソールから実行するには, S3 コンソールに行き,バケットの中身を開いたうえで,すべてのファイルを選択し, "Actions" → "Delete" を実行すればよいい.
コマンドラインから実行するには, 次のコマンドを使う. <BUCKET NAME> のところは,自分の バケットの名前 ("BashoutterBucketXXXX" というパターンの名前がついているはずである) に置き換えることを忘れずに.
sh
$ aws s3 rm <BUCKET NAME> --recursive$ aws s3 rm <BUCKET NAME> --recursive小括
ここまでが,本書第三部の内容であった.
第三部では,クラウドの応用として,一般の人に使ってもらうようなウェブアプリケーション・データベースをどのようにして作るのか,という点に焦点を当てて,説明を行った. その中で,従来的なクラウドシステムの設計と,ここ数年の最新の設計方法であるサーバーレスアーキテクチャについて解説した. (#sec_intro_serverless) では, AWS でのサーバーレスの実践として, Lambda, S3, DynamoDB のハンズオンを行った. 最後に, Hands-on #6: Bashoutter では,これらの技術を統合することで,完全サーバーレスなウェブアプリケーション "Bashoutter" を作成した.
これらの演習を通じて,世の中のウェブサービスがどのようにしてでき上がっているのか,少し理解が深まっただろうか? また,そのようなウェブアプリケーションを自分が作りたいと思ったとき,今回のハンズオンがその出発点となることができたならば幸いである.